02.03.25: AGI 的价格
到底是边际改善还是星际大战?


“便宜,更便宜,最便宜。”
过去一周,AI 领域爆发了一场史无前例的价格战。DeepSeek 的 R1 模型以每百万 token 0.55 美元的输入成本、2.19 美元的输出成本,打破了行业定价的默契。OpenAI 迅速跟进,推出 o3-mini,虽然价格略高(输入 1.1 美元/百万 token,输出 4.4 美元),但已远低于市场预期。Google 的 Gemini 2.0 则选择暂时免费,像是在等待一个合适的出价时机。
要理解这场价格战背后的深意,我们需要从成本曲线说起,看清竞争格局的分化,理解信仰的分歧,最后思考什么才是正确的时机。
成本前沿曲线
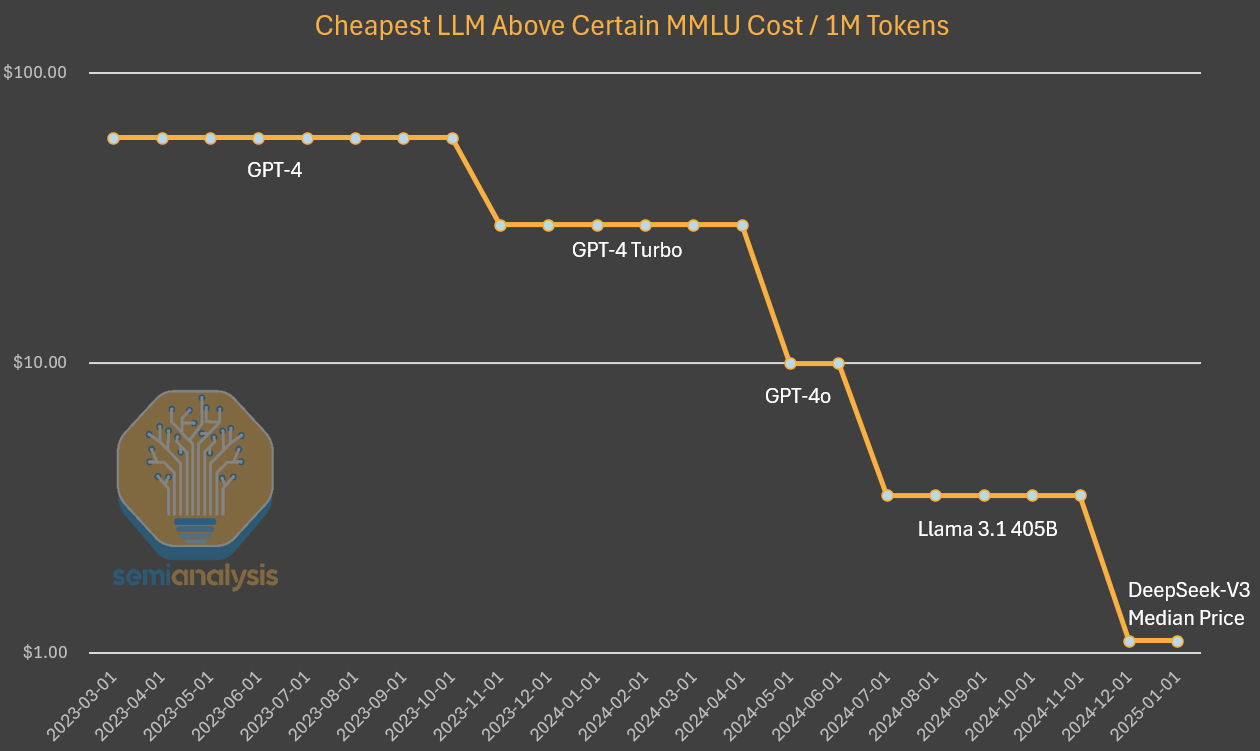
过去一周,AI 领域爆发了激烈的价格战。DeepSeek 推出的 R1 模型凭借惊人性价比引发关注:输入成本为每百万 token 0.55 美元,输出成本 2.19 美元。而 OpenAI 新发布的 o3-mini 虽然比 R1 贵,但也以输入 1.1 美元/百万 token,输出 4.4 美元的价格出乎很多人的意料——毕竟这个价格比 GPT-4o 还要便宜,更不要说和 o1 相比。与此同时,Google 的 Gemini 2.0 Flash Thinking 仍处于免费使用阶段,尚未公布定价。
根据 Semianalysis 的研究,AI 领域的算法进步速度惊人。每年算法效率提升约 4 倍,这意味着要达到相同的能力,所需计算量每年减少 75%。Anthropic 的 CEO Dario 甚至认为,算法进步速度可能达到每年 10 倍。就推理定价而言,达到 GPT-3 水平的成本已经下降了 1200 倍。
到目前为止,我们看到这种模式的结果是,人工智能实验室花费了更多的绝对美元来获得更智能的产品。据估计,算法进步的速度为 每年 4 倍,这意味着每过一年,实现相同功能所需的计算量就会减少 4 倍。Anthropic 首席执行官 Dario 认为,算法进步速度更快,可以带来 10 倍的改进。就 GPT-3 质量的推理定价而言,成本下降了 1200 倍。
在调查 GPT-4 的成本时,我们发现成本也有类似的下降,尽管在曲线的早期阶段。而成本随时间差异的减小可以用不再像上图那样保持能力不变来解释。在这种情况下,我们看到算法的改进和优化使成本降低了 10 倍并且能力提高了。
@indigo11 在 X 上解释 道:
AI 模型的商业化进程很可能出现类似芯片产业的“前沿与追随”并存格局:“前沿模型” 依靠新一代推理能力赚取高额利润;“追随模型” 则以相对较低价格抢占中低端或更多场景市场;双方都持续增长对算力(GPU 等硬件)的需求,进一步刺激芯片企业的发展。
这么看来,o3-mini 的定价更像是一个“跟随模型”,而真正的“前沿模型”还要等到 4-6 周后发布的 o3 才能看到。
Latent Space 的分析显示,OpenAI 最近对 o1-mini 进行了 63%(2.7 倍)的降价,o3-mini 的定价与之持平。然而,这个降幅远未达到与 DeepSeek R1/v3 价格曲线匹配所需的 25 倍。
从下图可以看到, 2025 年 1 月,在 Deepseek 的 V3 和 R1 两个模型推动下,成本前沿曲线向右移动,也就是说,获得同等智能水平的成本持续下降,这个结论和 SemiAnalysis 得到的类似。唯一的不同是,两者采用的基准测试不同,我将在后文中再来回顾基准测试的问题。
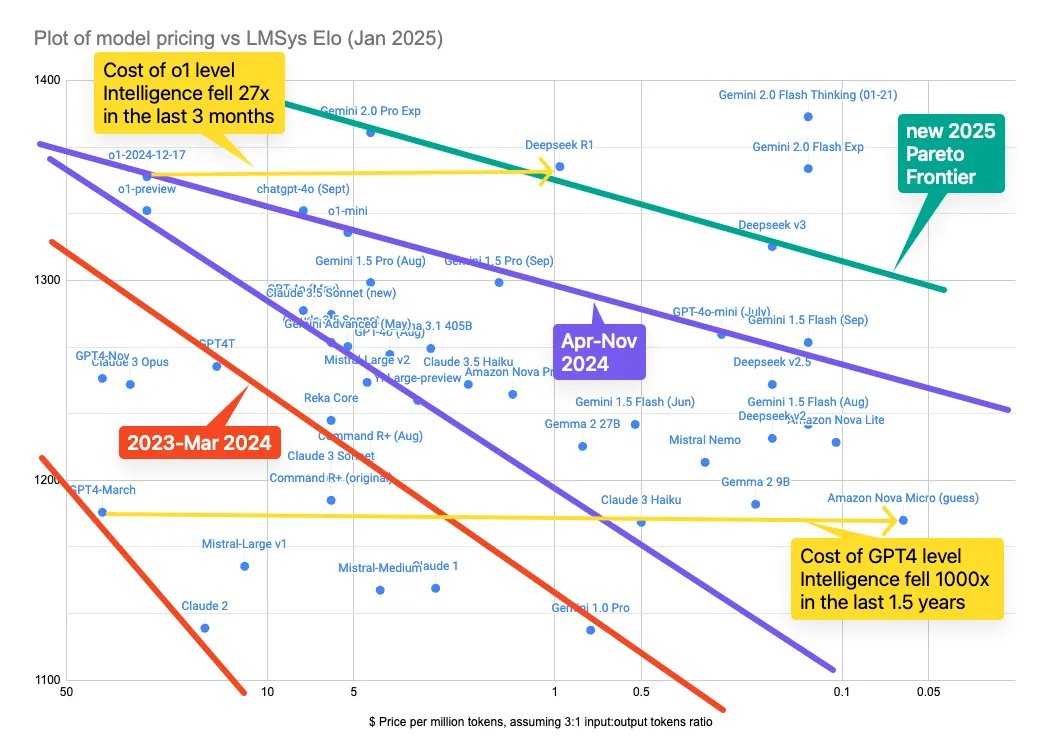
Latent Space 的文章发表在 o3-mini 正式发布之前,但他们很明智的预测了推理模型成本的大幅下降。但他们未能预测到的,是 o3-mini 大幅提到的输出速度。这不仅仅大大超出了 o1 时代的那种“思考几秒”才能得到结果的范式,也大大超出了很多尺寸较小的模型的输出速度。成本、速度、智能水平几个因素叠加,有力的拓宽了推理模型的应用场景。
竞争显然加剧了,但这场赛跑的终点却不一定是所有人想的那样是 AGI。
竞争分化
每一个新模型发布之前,有一项重要的工作就是进行基准测试,并将测试结果以模型卡(Model Card)的形式作为模型性能的表示放到发布公告中。
在本文开头部分提到的两个性能 - 成本曲线,实际上采取了完全不同的两种基准测试来衡量模型能力。
SemiAnalysis 采用的 MMLU 最早发布于 2021 年,它是 "Massive Multitask Language Understanding" 的缩写,用于评估模型在多任务语言理解能力,包含了来自不同领域的任务和问题,涵盖了从小学水平到专业水平的知识,涉及科学、人文、数学等多个学科。由于模型能力的快速提升,这个测试已经出现“饱和”的情况:很多模型都可以达到很高的分数。2024 年,MMLU Pro 发布,提升了基准测试的难度,以更好的评估模型能力。类似的基准测试还包括上面提到的 GPQA (Google‑Proof Q&A Benchmark) 以及 HLE (Human's Last Exam)、MATH、HumanEval 和在 o3 发布时备受关注的 ARC AGI 等。
Latent Space 则采用了 LMSys Elo。这是一个基于社区用户投票的众包形式进行的基准测试。在这个“竞技场”中,用户可以并排与两个匿名模型聊天,并投票选出哪一个更好。这种众包数据收集方式被认为更接近于人类在现实中使用 AI 模型的方式。然而,这些排名受到社会因素的影响,例如:用户不可避免的会偏好与他本人观点一致的回应。这些误差即便在引入了用模型做裁判(LLMs as Judges)的方法也难以避免。因此,类似 MMLU 和 GPQA 的评估方法仍是业界主要关注的对象。
无论哪一种评估方法,都不可避免的出现偏差,从而让模型能力的真实情况更令人迷惑。但更重要的问题在于,业界没有形成如何评估模型通用能力的共识,上述提到的基准测试大部分都偏重于测试一种能力,有点像是专业考试。特别是在数学和编码能力方面,已经成为近来推理模型重点突破和竞争的方向。在 Deepseek R1 和 OpenAI o3-mini 的模型卡上,业界最关注的也是相关基准测试的分数。
原因可能有两个:一是这些领域的测试相对客观和标准化,二是这些领域更可能代表“智能”的进化,模型在这些能力上的进步可能带来它自我迭代能力的觉醒。
但是,数学好,能写代码,并不能代表 AGI 中的“G”——通用性。一个典型的例子正是“务实派”所关心的 Agent 解决问题的能力。在现实世界中,大量任务的评估实际上并不是客观的,也并不能通过数学或编码能力来推导。简单的购买新年礼物、做旅行计划等生活场景,都很可能需要主观评估,而这些是目前的基准测试未能考虑的。
然而,基准测试是模型研发的风向标。基准测试很可能在无意中引导了模型走向在特定领域的竞争分化。
以刚刚发布的 o3-mini 为例。这个模型在多个基准测试中跑赢发布于数月之前的 Claude 3.5 Sonnet。但在实际使用中,人们却发现,在编码、创意写作等多个场景下,Sonnet 仍更能满足人类需求,Cursor 团队也在 推文 中表示更偏好 Sonnet。一种简单的描述是:o3-mini 的代码更像一个纯粹的理科生,简单干脆,但缺少一点灵性。而 Sonnet 则表现出更好的通用能力,能够更平衡的考虑多种不同维度,产生更令人满意的结果。
然而,o3-mini 在成本和性能上比 Sonnet 更优,这当然可能是受到了 R1 的竞争影响,但这可能意味着,o3-mini 这样的模型更可能沿着杰文斯悖论的叙事快速拓展使用场景,但同时,也丧失了作为“前沿模型”赚取高利润的可能。
另一个例子是几乎在同时间发布的 Mistral Small 3,主打的就是在 GPT-4o mini 相仿的性能上,速度更快,成本更低。
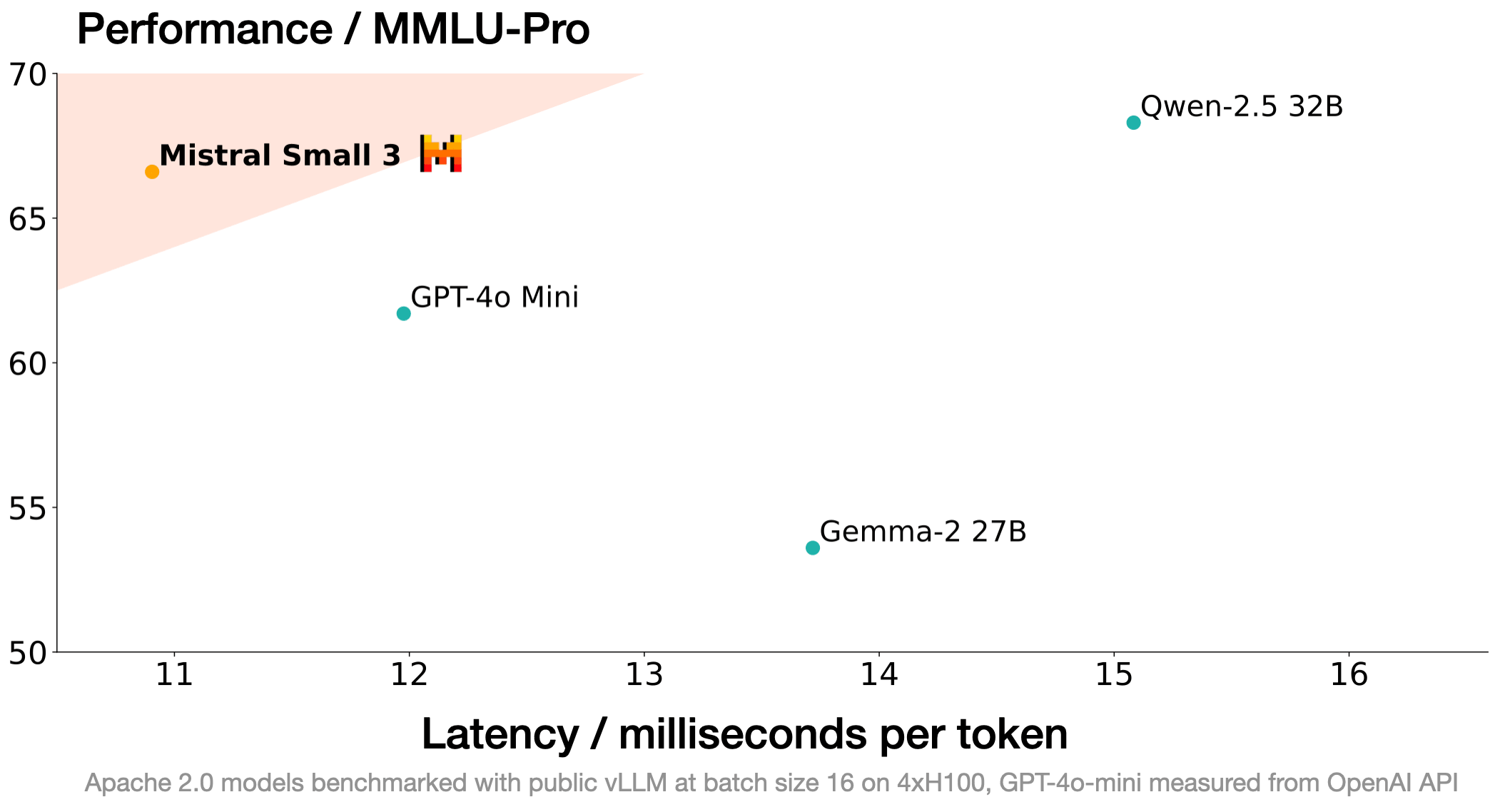
上图来自 Mistral 官方放出的模型能力(MMLU-Pro)和输出速度的对比图,越是在图的左上方,模型能力越强,输出速度越快。在 MMLU-Pro 官方给出的 排行榜 上,Mistral Small 3 的分数大概能排在 20 几名。在实际使用中,对一篇中等长度的文章进行总结,仅仅需要 2 分钱人民币,仅需要 1-2 秒即可返回完整结果。
开源和蒸馏无疑会加速模型成本下降的速度,它牺牲了模型获得通用智能的可能性,但它更接地气,可以更好的扮演各类 Agent 的角色,在具体场景中解决具体的问题。而价格和成本一定是获得市场的关键要素。两年前,我就和彼时还担任知乎 CTO 的面壁智能 CEO 李大海讲:面壁可以做模型界的“拼多多”,这个称号现在被 Deepseek 拿走了,但这个判断就是基于人性中对价格敏感度的理解,依照这个逻辑,杰文斯悖论上并不令人意外。
信仰分歧
我在前一篇文章中说,AGI 是一种信仰。这就意味着并不是所有人都坚定的相信这个信仰。在“星际之门”这样的宏大叙事下,这个信仰被赋予了超越技术的多重意味,其中当然有朴素的理想主义,但也一定有资本和政治利益在其中。
我做了一些简单的搜索,看看科技巨头们对 AGI 的态度到底如何,结果让我自己也有点吃惊,他们对 AGI 信仰的看法是明显分化的:
一派是信仰派,以 OpenAI、Anthropic 和英伟达(5 年内实现)为代表,Elon Musk 也表现得更激进激进(2 年内)。微软的 Satya Nadella 则显得有点摇摆,特别是在最近的“星际之门”发布后以及财报上。
另一派则是务实派,以 Apple(基本未在公开场合发表看法)、Meta(关注投资回报)、Amazon(马拉松的前三步)、Alphabet(AI 进展将变得更困难)、Salesforce 的 Marc Benioff(AGI 尚未到来)为代表。暧昧的 Microsoft 也可以算在务实派里,毕竟 Satya Nadella 最早讲出了 LLMs are becoming commodity 这样的话。这些在位者更偏爱的词汇是 Agentic AI,因为后者更可能在短期看到回报。
不难理解,在“信仰派”中,有 OpenAI 这样的创业公司,也有卖铲子的 Nvidia,还有 Musk 这样的狂人,这些人都需要不断把故事讲大,创造焦虑和竞争,才能支撑更大的资本投入。我相信,这并不是一个完整的阴谋论叙事,但其中有真有假,存在空中楼阁的成分。
务实派则很现实,他们在这个阶段需要每年投入数百亿的真金白银。这是一个二难选择:投入则意味着当下的业绩压力,不投入则担心上不了未来的牌桌。Amazon、Microsoft 和 Google 三家都有自己云计算业务,Meta 作为一家纯粹的消费互联网公司,也投入了体量相当的资本支出,笃定自己的变现能力可以在未来产生足够的收益。Apple 的态度保守而暧昧。Salesforce 作为 SaaS 的龙头企业,拥有庞大的客户群,自然希望通过 Agents 收到更多订阅费用。
从资本市场角度看,信仰派的估值都很高,特别是 Tesla,股价和业务基本面几乎毫不相干;而务实派的估值则相对较低——虽然也有一定的泡沫因素在,但相对这些公司的增长而言,还可以理解。这些公司基本都建立了比较明确的将模型能力转化为现金流的商业模式。
R1 和 o3-mini 的定价和性能是务实派所希望看到的,尚未公布的 Gemini 2 推理模型的价格也可能处于一个可比的区间内。“追随模型”在更低的成本上,每次替代原有工作流程的 20%,而非对现有劳动力市场产生结构性替代,在部署中遇到的障碍会更少;边际改善的效率提升,而不是天降奇兵式的颠覆和替代,更可能产生良好的回报。
对务实派而言,以低成本为优先要素的竞争分化则意味着能在更短的时间内找到应用场景,也就能为资本支出找到回报的路径。
价格战打不出 AGI,对于信仰派而言,还需要为 AGI 寻找新的叙事逻辑。
大国竞争叙事
当星际之门计划发布的时候,人们有些惊讶,为什么 OpenAI 出现了,但 Microsoft 却没有出现,同时,Nvidia 的 Jensen Huang 却出现在中国。
在 Deepseek R1 发布后,Anthropic 的创始人和 CEO Dario Amodei 很快撰文呼吁针对中国进行更强硬的技术出口管制。同期,美国的云计算平台和推理服务商开始上线部署在美国数据中心的 R1 服务,Perplexity、Cursor、Raycast 等 AI 应用也开始上线“数据不会发给中国”的 R1 模型。
在中国国内,Deepseek 饱受 DoS 攻击之苦,整个春节期间,官方服务基本都无法正常使用。直到推理加速服务商硅基流动上线了基于华为芯片的 R1 服务,国内才有了可以“满血”使用的 Deepseek R1 API。这个消息也被 Marc Andreessen 看到,在 X 上转发了相关推文,就在几天之前,他标志性的把 R1 的发布比喻成 AI 的 Sputnik 时刻。
在大大小小的行业群、社交媒体上,AI 的主流叙事快速转向为中美之间的力量抗衡。对于 AGI 的信仰派而言,这无疑是催动下一轮资本支出的好故事。故事的主线不再是如何(更快更好的)达到 AGI,而是如何不要落后于对手,甚至是如何阻碍对手。
这种政治叙事下的竞争和市场机制下的竞争完全不同。市场机制的核心是通过价格信号传递供需关系,进行良性的优胜劣汰。而这种猜疑链下的竞争则不顾供需,只是大力出奇迹。在这样的背景之下,星际之门计划中 Microsoft 的态度就很容易理解——Microsoft 的暧昧态度意味着 Satya Nadella 的内心住着一个务实派。
Trump 上台后的关税大棒也开始挥舞,在市场分歧加大的情况下,很容易莫名其妙带崩股市。这种砸盘的逻辑,或许是要让务实派们被迫成为信仰派。毕竟,宏大叙事只能有一个,在这样的叙事下,没人能打自己的小算盘。
贸易政策,极有可能成为超越货币政策的“看得见的手”,左右整个 AI 叙事的风向。
正确的时机
2000 年 6 月,距离 NASDAQ 的史诗性崩盘还有几个月时间,纽约时报的专栏作家 Alex Berenson 以 Rapid Growth Makes Cisco A New Leader 为题,写了一篇短文。开头这样写道:
在股市永无休止的马戏团中,任何时候,都有一家公司站在聚光灯下。它可能不是世界上最大的公司,也不是最赚钱的公司,但不知何故,它既反映了市场的整体走势,又引领了市场的整体走势。
行文中,他努力平衡自己的语气,尽量不要透露一丝倾向,但毫无疑问,在 3 月出现过一次下跌之后,人们都开始谨慎起来。
2025 年的 Nvidia 与 2000 年的 Cisco 有很多相似之处。
在 Deepseek R1 风波后,看空 Nvidia 的声音不绝于耳。模型混战,价格竞争,行业很可能出现“微笑曲线”的情形:价值捕获集中在最上游和最下游,而 Nvidia 的高性能芯片以及专有软件面临被绕开的风险。
Microsoft 前高管 Steven Sinofsky 在文章 DeepSeek Has Been Inevitable and Here's Why (History Tells Us) 中用 AT&T 与思科的历史案例来警示当前的 AI 芯片市场。就像 AT&T 低估了基于 IP 的网络技术一样,当前市场可能也在低估替代技术的潜力。
共同基金 Harding Loevner 在 2023 - 2024 年做了一系列的基本面分析,用很简洁的行业分析手段,指出了 Nvidia 面临的竞争格局:
- 客户集中度高,主要客户都具备向后整合能力
- 亚马逊、谷歌和微软都在开发定制芯片
- AI 基础设施支出增速放缓后,市场将寻求更经济的替代方案
- 价值可能从硬件转向软件和服务层
尽管 Nvidia 的估值比 Cisco 的巅峰时期(2000 年 3 月,Cisco 的市盈率为 201 倍)还低了许多,在 2024 年第一季度,这家基金将持仓多年的 Nvidia 股票平仓,转而投资行业下游的 Microsoft。到目前来看,这个平仓的时机似乎并不明智。
让我来分享一个发生在 2000 年代的投资故事,帮助我们理解关于时机的问题。
1995 年末,37 岁的 Jeff Vinik,作为规模达 530 亿美元的富达麦哲伦基金(Fidelity Magellan Fund)的掌舵人,看到了一些让他不安的迹象。科技板块开始呈现出泡沫化的特征,让他想起了金融史上那些投机泡沫的案例。当其他人还在科技股上涨的节奏中欢快起舞时,Vinik 做出了一个大胆的决定——这个决定最终定义了他的职业生涯,只是并非以他期待的方式。
在短短两个月内,他将麦哲伦基金的科技股持仓从 43% 砍到不到 25%。到了 1996 年春天,这个比例进一步降至惊人的 3.5%。取而代之的是,他重仓了当时被认为是最无聊的投资品种:国债和现金。他的理由?他认为“未来一两年内”债券的表现会优于股票。
这个决定不仅仅是战术调整,它简直是对 90 年代牛市三大信条的亵渎:
- 长期来看,股票永远战胜债券
- 不要试图择时
- 买入好公司并长期持有
市场的反应又快又狠。利率上升,重创了他的国债仓位。与此同时,科技股继续着疯狂的上涨。当麦哲伦基金的三年收益率跌破标普 500 时,Vinik 的命运就已注定。他很快就主动离职了,成为了给所有基金经理的警示:别对抗市场趋势,即使你认为它是错的。
这个故事最具讽刺意味的转折是:Vinik 是对的,而且是完全正确的。如果投资者在 1996 年跟随他的策略,就能避开 2000 年初的科技股崩盘。在接下来的七年里,他那个“时机不当”的转向债券的决定,实际上跑赢了标普 500。
在离开 Fidelity 后,Vinik 成立了自己的对冲基金,在短短四年时间里,他为投资者赚取了超过 5 倍的的回报。
在 2000 年泡沫破裂的声响中,Vinik 宣布退休。
Vinik 的故事在今天显然颇具现实意义。它提出了一些令人不安的问题:我们是否正处在类似的非理性繁荣时期?
更重要的是,在一个“太早或太晚等同于错误”的世界里,我们该如何平衡信仰与时机?
我们会有足够的时间来证明自己是对的吗?
本期阅读推荐 Links + Notes 包含以下内容:
- 对话 Daloopa CTO Jeremy Huang: 创业团队如何通过大量客户访谈找到产品市场匹配,以及在金融科技领域打造可信赖的 AI 产品的经验分享。
- The Agent Reasoning Interface: 前 Anthropic/OpenAI 工程师 Karina Nguyen 深入解析 AI 模型评估的难点,揭示了基准测试背后的复杂性和局限性。
- The Law of Displacement Speed: Scott Belsky 提出“替代速度定律”,分析了当应用能快速替代彼此时,最终会导向商品化或平台级替代的现象。
- DeepSeek Has Been Inevitable: 前微软高管 Steven Sinofsky 通过回顾互联网泡沫时期的经验,解释为什么像 DeepSeek 这样的新玩家能够挑战现有巨头。
- 莫尼什·帕伯莱:投资前你要弄清楚的两个问题: 对科技股估值的简单理解。